Computational Social Science 2 (Simulation)

Introduction
As computing power has increased and costs have dropped, computational tools like simulation have expanded beyond simple supplementary methods. Economists, for example, use simulation extensively in macroeconomics through Dynamic Stochastic General Equilibrium (DSGE) models—an important topic in graduate-level economics. This new and advanced tool has enriched conventional modeling and data analysis approaches. Yet, should this expansion justify calling the field “computational social science”? Or is there something deeper?
This part addresses that question directly by focusing on a specific type of simulation—Agent-Based Modeling (ABM)—and examining how and why ABM contributes to a new epistemological perspective in social science research.
Agent-Based Modeling as “Simulation”
When people talk about simulation in computational social science, they often refer to ABM. While definitions vary, the core idea remains consistent:
ABM models the dynamics of decision-making by individual agents who interact both with each other and with their environment.
Key concepts are individual, interact, and dynamics. Put simply, ABM is a way of modeling the dynamics that emerge from how individuals interact. Despite being merely one form of modeling, ABM can be considered a major pillar of the new field called “computational social science.” One major reason is illustrated in Thomas Schelling’s classic work, Micromotives and Macrobehavior. Schelling demonstrated how decentralized decisions made by individuals can produce complex patterns at the collective level—patterns that may not align with the preferences or features of those same individuals. This phenomenon exemplifies “emergence”: micro-level rules leading to unexpected macro-level outcomes.
Elinor Ostrom, in her book Understanding Institutional Diversity, similarly highlights how these patterns are so complex that computational simulations can be more suitable than mathematical approaches. Indeed, such emergent phenomena are ubiquitous not only in human societies, but also in animal herds, insect colonies, and even ecological systems.
Should ABM be used to study all of these forms of social or natural phenomena? Probably not. In many applied research scenarios, if you already have robust datasets and established statistical or mathematical frameworks, a conventional approach will be simpler and more rigorous.
When (and Why) ABM Outperforms Traditional Methods
However, there are cases where ABM becomes critical. It’s somewhat akin to the Bayesian method. You don’t necessarily need to use it, but Bayesian methods become indispensable when you want to incorporate prior knowledge or handle vast parameter spaces with MCMC (Markov Chain Monte Carlo).
Below are three specific conditions in which ABM can shine:
1. Insufficient or Fragmented Data
- Archaeology Example
In archaeology, data are often fragmented. Gaps between pieces of evidence are large, and it’s unclear if those gaps can ever be filled. ABM can theoretically fill these data gaps, allowing researchers to test hypotheses about how ancient societies might have behaved or evolved, even when direct observations or measurements are missing.
- The “Oceans of Data” Paradox
We live in an era often described as an “Ocean of Data.” In principle, vast amounts of data are generated daily and stored both in the physical world and online. Yet the real question is how much of that data is relevant and usable—like how much water is actually drinkable. In many academic fields, data collection tailored to a specific research question is often too expensive or time-consuming, forcing researchers to rely on secondary data that may not fit perfectly.
As a result, researchers sometimes face the streetlight effect—focusing on questions for which data are conveniently available rather than on the questions that actually matter. ABM helps avoid this trap by enabling the modeling of theoretical scenarios or by simulating the missing pieces. This approach allows researchers to chase their “lost keys” where they actually dropped them, not just where the light is.
2. Need for Experiments That Are Impractical or Impossible in Reality
The gold standard for causal inference is experimental design. But in social sciences—outside of some controlled lab experiments in behavioral or microeconomics—true experiments can be constrained by ethical, financial, or logistical issues. Enter simulation.
- Pandemic Policy Example
Imagine a pandemic with a very limited supply of vaccines. Deciding which regions or demographic groups get priority is critical. You cannot ethically run real experiments to see which allocation saves more lives or how people react under different distributions. But with ABM, you can construct plausible models of populations, infection dynamics, and behavioral responses to different policies. By running these virtual experiments, you gain insight into how different vaccination strategies might unfold in reality.
This power to run counterfactual scenarios inexpensively and ethically is one of ABM’s greatest advantages, especially when real-world experimentation is untenable.
3. Studying Complex Adaptive Systems
Emergence describes how individual-level actions or interactions give rise to complex patterns. Examples include phenomena such as tipping points, path dependence, and phase transitions. Characterized by non-linear and high-dimensional generative processes, emergence reveals how local interactions can shape global outcomes. Coupled Systems like Social-Ecological Systems (SES) also exhibit these features. Collectively, these phenomena are examined through the lens of complex adaptive systems.
ABM is an optimal tool for investigating complex adaptive systems because it allows researchers to:
- Define heterogeneous agents with distinct preferences or behaviors.
- Introduce local interactions.
- Observe how macro-level patterns evolve over time.
Distinguishing Computational Social Science from Conventional Fields
The three conditions mentioned above are common in social science research, calling for a tool beyond what traditional regression models or machine learning alone can handle. ABM is not employed merely because it happens to be available or familiar, but rather because it is the most suitable simulation tool when these specific conditions arise. In these contexts, ABM provides the basis for distinguishing computational social science from other approaches.
Hence, we can see a subtle but important difference between:
- Data Science or Computer Science, where researchers tackle social science questions using familiar computational tools.
- Computational Social Science, where the social science questions—especially those that fit the three conditions above—drive the choice of computational modeling.
As noted in Part 1, the boundary is not always crystal clear, nor does it need to be. Still, ABM can offer a critical epistemological grounding when traditional methods hit a wall.
Tools : NetLogo and Python
Learning ABM can be a challenge for social scientists who may not have a programming background. Many start with NetLogo, a language designed specifically for ABM. However, as researchers explore further, they may encounter models written in a variety of languages (C++, Java, Python, etc.). This often prompts the question: Which language should I choose?
NetLogo vs. Python
- NetLogo
NetLogo is beginner-friendly with a straightforward syntax and a rich Model Library, featuring numerous ready-made examples. Two highly recommended textbooks are:
- An Introduction to Agent-Based Modeling by Uri Wilensky and William Rand.
- Agent-Based and Individual-Based Modeling by Steven Railsback and Volker Grimm.
- Python
Python, one of the most popular languages in data science, is also used extensively for ABM—often via frameworks like Mesa. Python’s versatility and powerful libraries for data manipulation (e.g., NumPy, pandas), visualization (Matplotlib, seaborn), and machine learning (scikit-learn, PyTorch, TensorFlow) can complement ABM work. If you already know R, picking up Python can feel familiar, as both are high-level scripting languages often used for data analysis.
Studies like Berceanu and Patrascu (2024) have shown that model outcomes tend to be similar regardless of whether you use Python or NetLogo, given the same underlying rules. However, Python code may be more verbose. For beginners, NetLogo remains the easiest place to start.
Consider the simplest model in NetLogo’s Model Library, “Wolf Sheep Simple 1.”
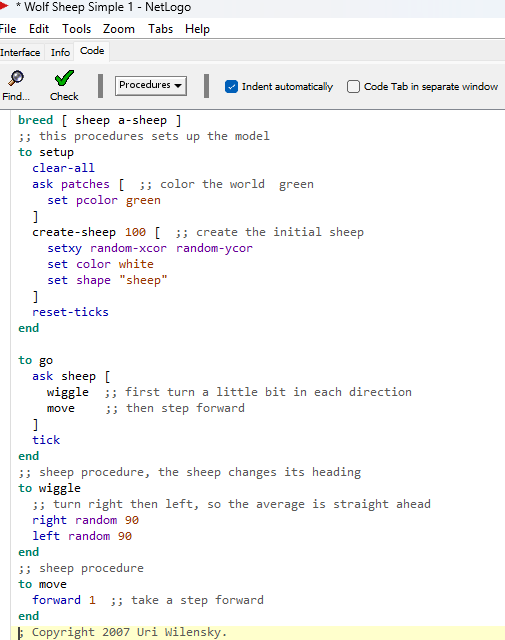
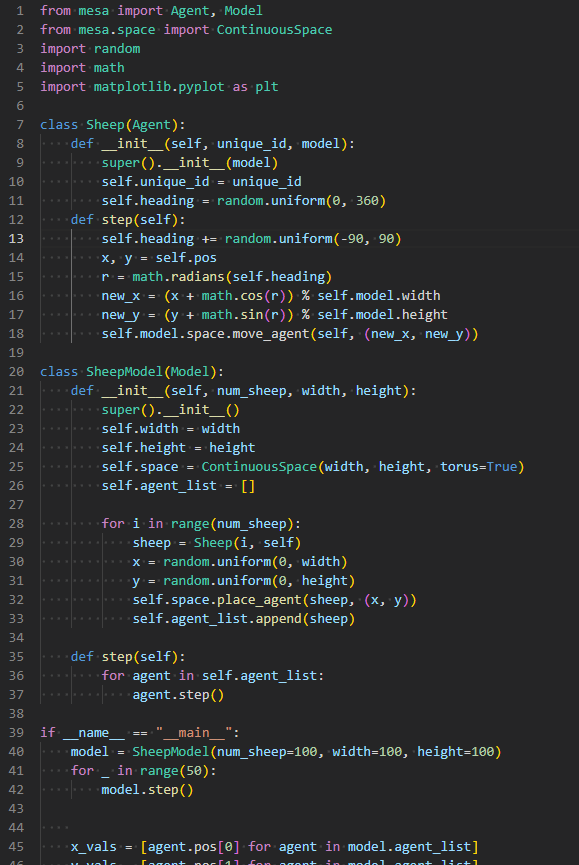
However, rewriting the same simple model in Python yields a much more complex script. And if you want to add visualization, you need even longer code.
Extending NetLogo with R or Python
Once you have a working NetLogo model, you might want to:
- Run large parameter sweeps (e.g., systematically varying dozens of model parameters).
- Statistically analyze model outputs with advanced libraries.
NetLogo has extensions for R and Python that let you run external scripts and retrieve values for further analysis. Meanwhile, packages like nlrx (for R) and NL4Py (for Python) allow you to control NetLogo from within R or Python scripts. This synergy lets you blend NetLogo’s simplicity with the analytic power and flexibility of external languages.
However, integrating multiple languages can introduce version or dependency conflicts, often involving Java. Any change in the versions of R, Python, or Java can trigger unexpected errors. From personal experience, R-based packages (like nlrx) seem somewhat more prone to these issues, but it ultimately depends on the specific environment and package versions you’re using.
Conclusion
During my PhD studies, I became fascinated by computational modeling in political economy. As I surveyed research in this area, I noticed many studies coming from computer science departments, using advanced computational techniques to explore political or economic topics. When I asked my advisor about this, he answered succinctly: “They do it because they can.”
This remark highlights a key difference:
- Researchers from computer science may choose a social science problem because it is an interesting application of their technical expertise.
- Researchers rooted in social science may turn to computational methods (including ABM) when they encounter conceptual or methodological barriers that conventional frameworks cannot surmount.
From an outside perspective, the outcomes might look similar, but the driving questions, assumptions, and even the interpretations can differ. I believe that computational social science should develop as a domain that acknowledges and leverages this difference, using computational tools to push social science research into territories previously out of reach.
This perspective motivated me to write about computational social science. Ultimately, the rise of computational social science is not merely about having more computing power or advanced methods. It is about reshaping how we frame social questions, design experiments (virtual or otherwise), and interpret the complex interplay between individuals and societies.
Reference
Schelling, Thomas C., 1978. Micromotives and macrobehavior.
Ostrom, E., 2005. Understanding Institutional Diversity.
Berceanu and Patrascu, 2024. "Comparative Analysis of Agent-Based modeling Frameworks for Signal Propagation in Complex Networks : Netlogo and Python Mesa."